Introduction to statistics in R for criminologists
Undergraduate techniques of data analysis (Brauer; IUB CJUS-K300)

The following assignments are designed to provide a (relatively) gentle introduction to elementary foundations of frequentist statistics using R via R Studio & R Markdown. They were created for Jon’s undergraduate statistics course (CJUS K300) and, in collaboration with Tyeisha Fordham, were adapted from earlier SPSS versions.
Here is an abridged syllabus for the course. Most of the assignments are based on exercises found in Bachman, Paternoster, & Wilson’s Statistics for Criminology & Criminal Justice, 5th Ed., which we refer to throughout as “BPW” book. When teaching the course, Jon pairs each R Assignment with a weekly Canvas assignment assessing comprehension of formulas and “by hand” statistical calculations.
Though initially designed for undergraduate students, the course is comparable to many introductory statistics courses that graduate students take in pursuit of Masters or PhD degrees in criminology/criminal justice. Certain features of the course (e.g,. book selection; certain R package choices) were designed with the goal in mind of easing the transition to R for students and faculty with prior experience using SPSS. Hence, these R Assignments may also provide a helpful bridge for graduate students prior to taking more advanced statistics courses that use R and, likewise, may be useful for criminologists at any educational or career stages interested in learning to use R for the first time.

Introduction: Tips, troubleshooting, and why R?
Before you begin the assignments below, we recommend watching this brief introductory video. In it, Dr. Caitlin Ducate explains why it is worth your time to learn data analysis skills in R/RStudio, describes basic features of the R language, highlights things you can do in R, and gives advice for troubleshooting with R.
Introductory video (by Caitlin Ducate)

here() package by @allison_horstAssignment 1: Getting Started in R
The purpose of this first assignment is to demonstrate that you have downloaded the “base R” and “RStudio” statistical programs and can open a SPSS datafile in RStudio. Additionally, you will learn how to create, edit, and knit an R Markdown file.
Video walkthrough for Assignment 1 (by Caitlin Ducate)


dplyr::mutate() by @allison_horstAssignment 3: Describing Data Distributions
Chapters 2 & 3 of B&P’s book focused on data distributions and displaying data with tabular or graphical representations. In this assignment, you will learn how to recode variables, generate frequency tables, and create simple graphs in R.
Video walkthroughs for Assignment 3 (by Caitlin Ducate)

Assignment 4: Central Tendency
BPW’s chapter 4 focused on measures of central tendency (e.g., mean, median, and mode,) and their advantages and disadvantages as single statistical descriptions of a data distribution. Likewise, in this assignment, you will learn how to use R to calculate measures of central tendency and other statistics (e.g., skewness; kurtosis) that us help standardize and efficiently describe the shape of a data distribution. You will also get additional practice with creating frequency tables and simple graphs in R.
Video walkthrough for Assignment 4 (by Caitlin Ducate)

ggplot2() by @allison_horstAssignment 5: Dispersion
BPW’s chapter 5 covered measures of dispersion, including variation ratio, range, interquartile range, variance, and standard deviation. We use measures of dispersion to summarize the “spread” (rather than central tendency) of a data distribution. Likewise, in this assignment, you will learn how to use R to calculate measures of dispersion and create boxplots that help us standardize and efficiently describe the spread of a data distribution. You will also get additional practice with creating frequency tables and simple graphs in R, and you will learn how to modify some elements (e.g., color) of a ggplot object.
Video walkthrough for Assignment 5 (by Caitlin Ducate)

dplyr::filter() by @allison_horstAssignment 6: Probability & Cross-tabulations
BPW’s chapter 6 provided an introduction to probability, including foundational rules of probability and probability distributions. In the current assignment, you will gain a better understanding of frequentist probability by learning to create and interpret cross-tabulations or joint frequency contingency tables and by calculating z-scores.
Video walkthrough for Assignment 6 (by Caitlin Ducate)
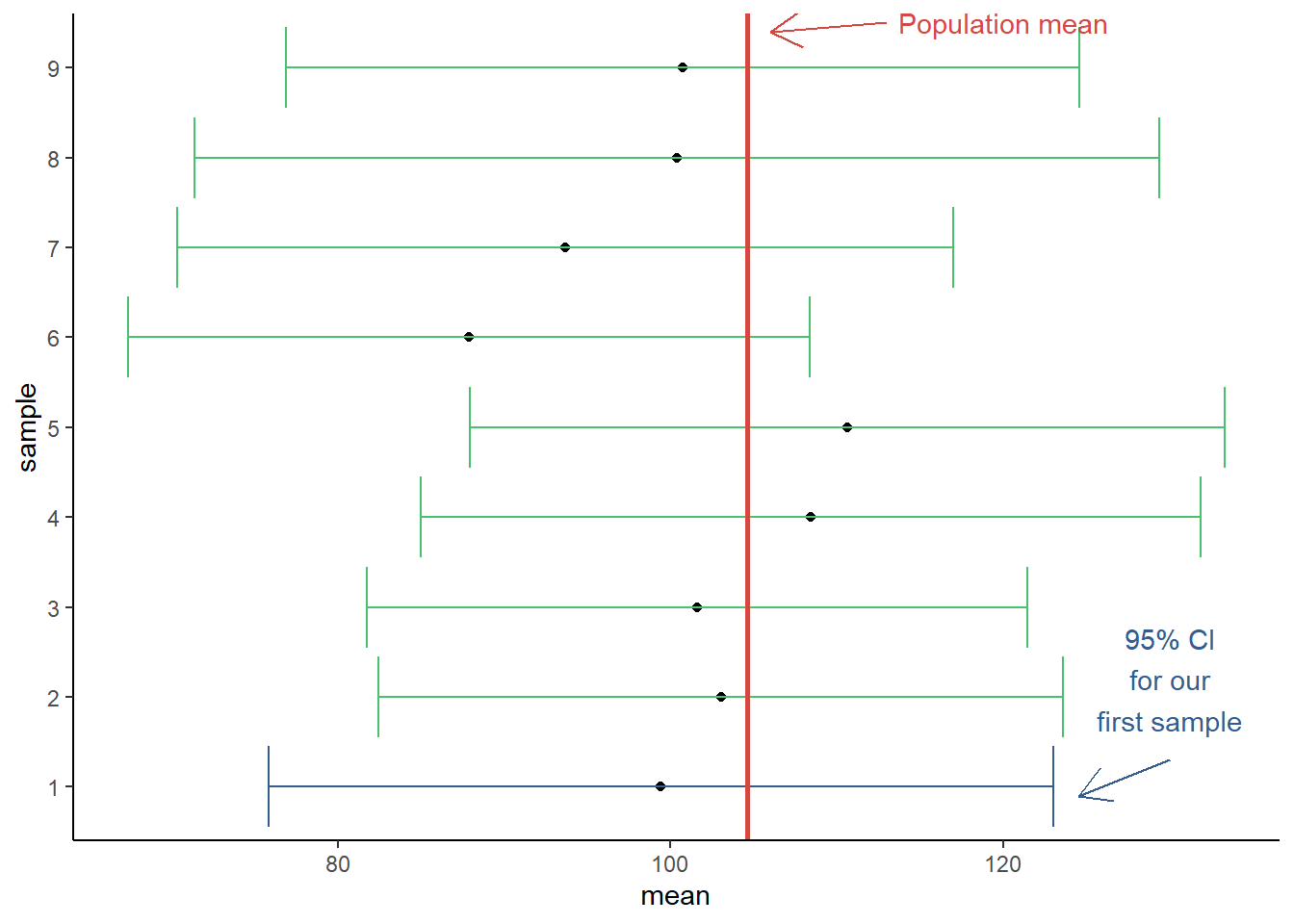
Assignment 7: Sampling Variability & Confidence Intervals
In this assignment, we dig deeper into the process of making statistical inferences about population parameters from sample statistics. For instance, you will learn to think about sample descriptive statistics (e.g., a sample mean or correlation coefficient) as point estimates of population parameters. Relatedly, following BPW’s chapter 7, you will learn how to calculate confidence intervals around a point estimate in R and to interpret them appropriately. Additionally, you will learn how to simulate data from a probability distribution, which should help you better understand sampling variability and the need for interval estimates.
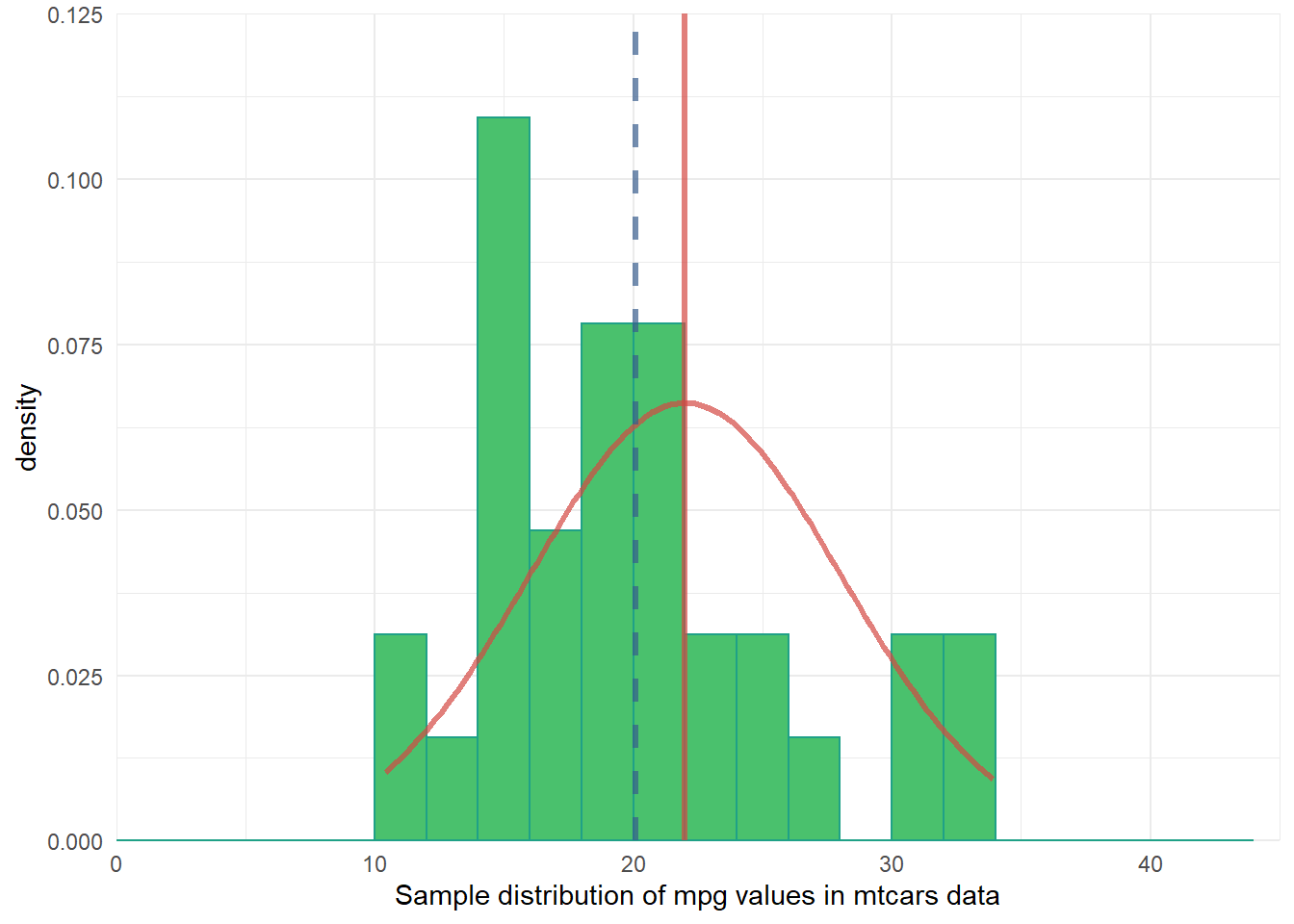
Assignment 8: One-sample Null Hypothesis Test
Following BPW’s chapter 8, in this assignment you will learn how to conduct a two-tail z-test and t-test and then, given the test results and the null hypothesis, to make an appropriate inference about the population parameter by either rejecting or failing to reject the null hypothesis. Along the way, you will explore plots of data distributions from random samples drawn from simulated population data. This exploration is intended to help you visualize the sampling distribution of a sample mean, which should lead to a better understanding of the underlying mechanisms that allow us to make valid population inferences from samples with null hypothesis significance testing.
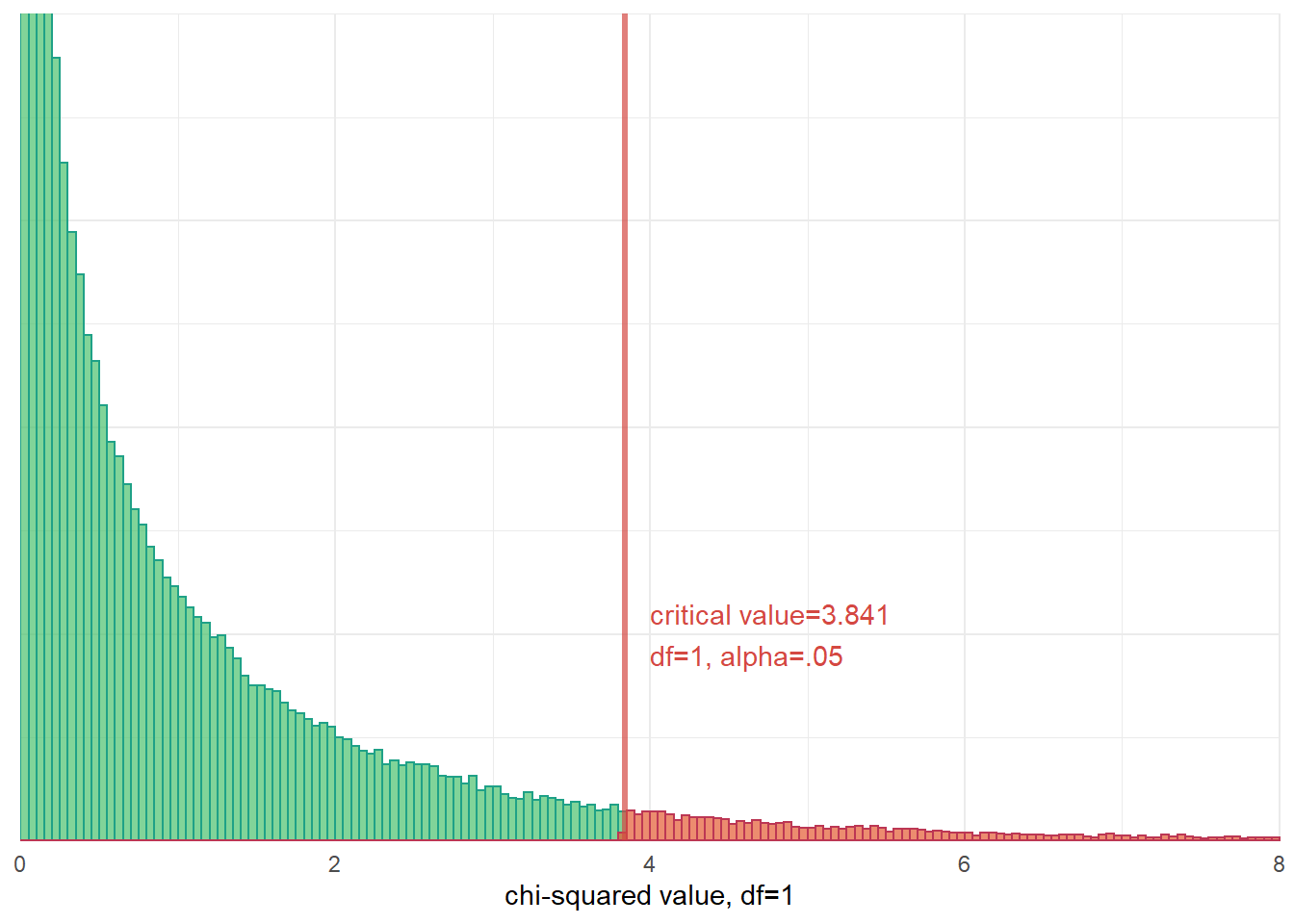
Assignment 9: Chi-squared Test of Independence
As in BPW’s chapter 9, in this assignment you will learn how to make population inferences about the relationship between two categorical variables by conducting a chi-squared test of independence on a sample contingency table (crosstab). Additionally, we will briefly introduce you to the phi-coefficient and Cramer’s V, two measures of association that can be interpreted to describe the strength of an association between variables in a crosstab.
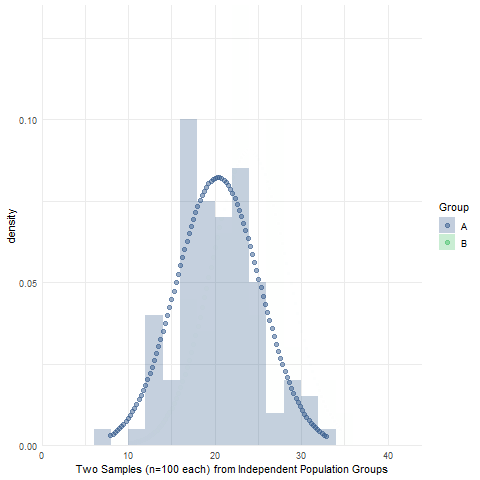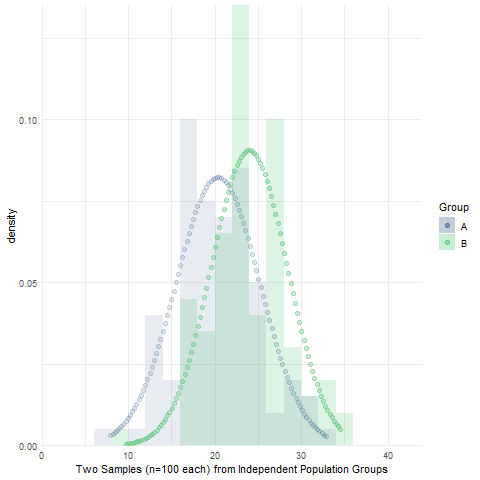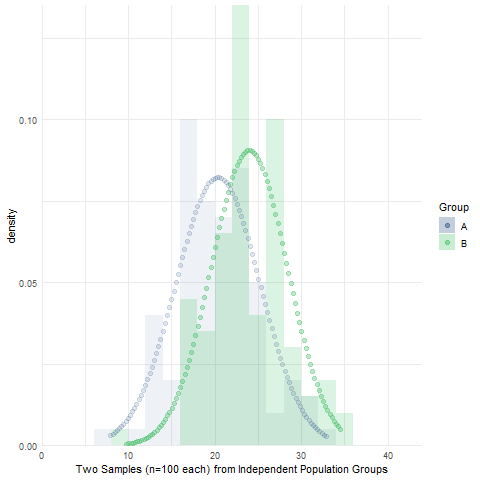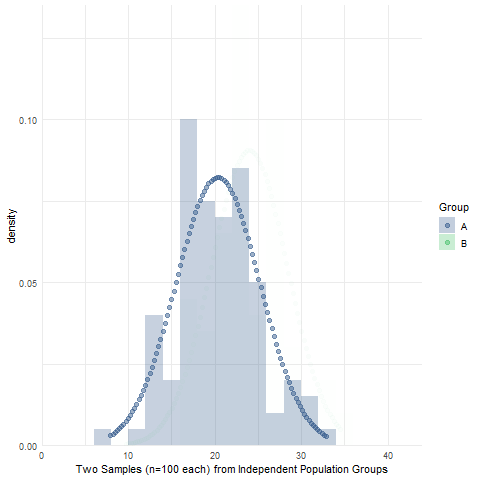
Assignment 10: Two-sample Null Hypothesis Test
BPW’s chapter 10 focused on null hypothesis tests to make inferences about the equality of two group means or proportions using sample data. Likewise, in this assignment, you will learn how to make an inference about the (in)equality of two population group means by conducting an independent sample t-test and then determining whether to reject or fail to reject the null hypothesis of no difference in population group means. We will also use simulations to visualize the sampling distribution of sample mean differences, briefly introduce Levene’s test of equality of population group variances, and introduce the half-violin/half-dotplot as a way to visualize variable distributions and potential outliers for two (or more) groups.
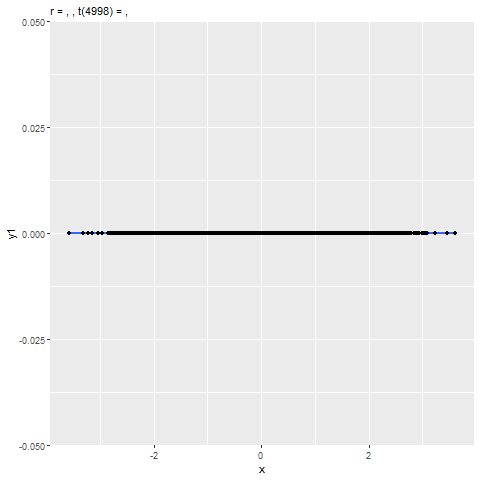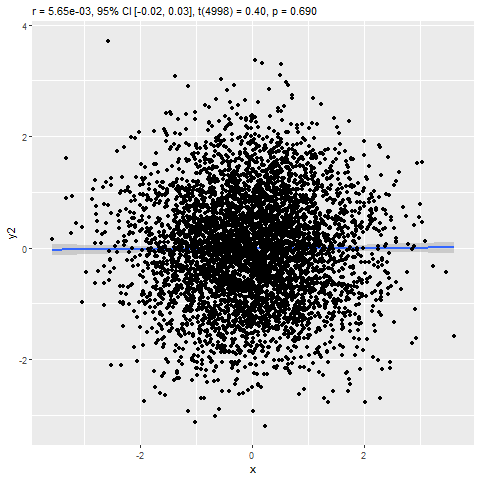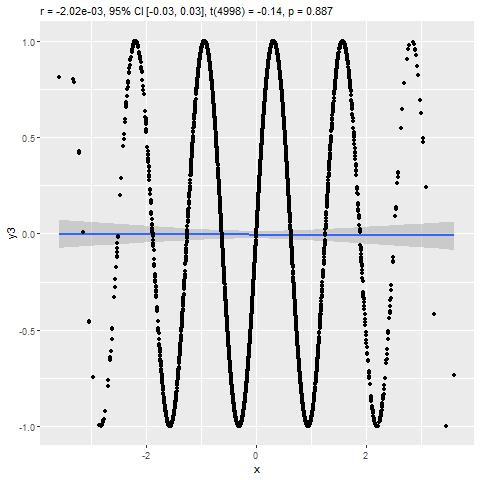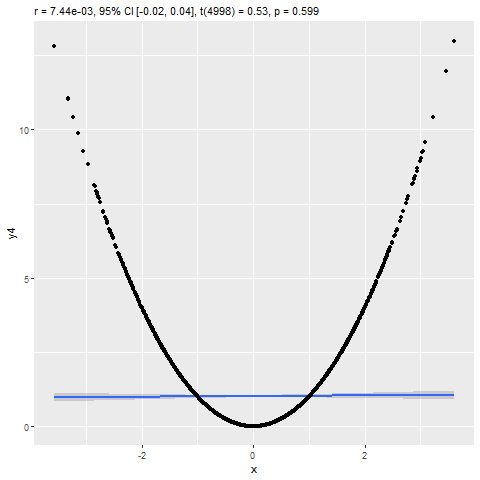
Assignment 11: Correlation & Regression
BPW’s chapter 12 explored describing the association between two continuous numeric variables using a scatterplot, Pearson’s correlation coefficient (r), and an ordinary least-squared (OLS) linear regression model. In this assignment, you will learn how to estimate the strength of a linear association between two numeric variables by calculating Pearson’s correlation coefficient (r) and predict expected values of a dependent variable (Y) from the values of a linearly correlated predictor variable (X) using a linear regression model. Additionally, you will learn to visualize the association with a scatterplot and be introduced to some tools for checking model assumptions and assessing the fit of your regression model to the data.
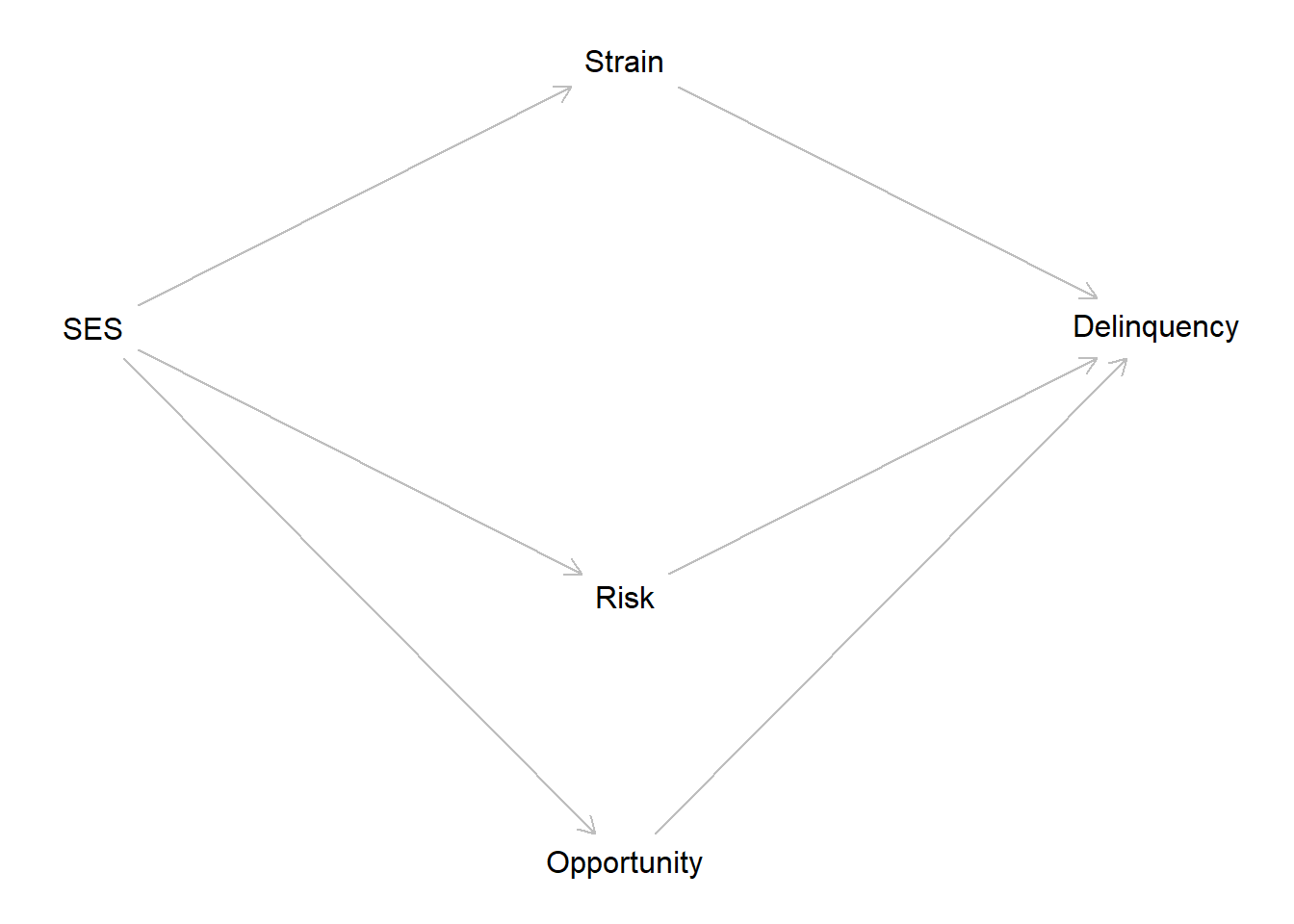
Extra Credit: Causation without Correlation
In the last assignment, you learned how to describe associations between two continuous numeric variables using a scatterplot, Pearson’s correlation coefficient (r), and an ordinary least-squared (OLS) linear regression model. In this extra credit assignment, you have the opportunity to put your skills to the test. For this activity, you will read and reproduce all code from the Causation without correlation blog post. Then, you will be challenged to extend the blog example with new simulated data containing three mediating mechanisms and attempt to interpret the results. This assignment will push you beyond the boundaries of what you have learned. Do not let that frighten or discourage you. As extra credit, any attempt is a worthwhile success and, if you choose not to attempt it, then you only fail yourself!
Reuse
Citation
@online{brauer_and_tyeisha_fordham,
author = {Brauer and Tyeisha Fordham, Jon},
title = {Introduction to Statistics in {R} for Criminologists},
url = {https://www.reluctantcriminologists.com/course-materials/1_ugrad_stats/},
langid = {en}
}